On Monday, the Raspberry Pi 2 was announced, and The Register’s predictions of global geekgasm proved to be about right. Slashdot, BBC News, global trending on Twitter and many other sources covering the story resulted in quite a lot of traffic. We saw 11 million page requests from over 700,000 unique IP addresses in our logs from Monday, around 6x the normal traffic load.
The Raspberry Pi website is hosted on WordPress using the WP Super Cache plugin. This plugin generally works very well, resulting in the vast majority of page requests being served from a static file, rather than hitting PHP and MySQL. The second major part of the site is the forums and the different parts of the site have wildly differing typical performance characteristics. In addition to this, the site is fronted by four load balancers which supply most of the downloads directly and scrub some malicious requests. We can cope with roughly:
| Cached WordPress |
160 pages / second |
| Non cached WordPress |
10 pages / second |
| Forum page |
10 pages / second |
| Maintenance page |
at least 10,000 pages / second |
Back in 2012, during the original launch, we had a rather smaller server setup. That meant we simply just put a maintenance page up and directed everyone to buy a Pi direct from Farnell or RS, both of whom had some trouble coping with the demand. We also launched at 6am GMT so that most of our potential customers would still be in bed, spreading the initial surge over several hours.
This time, being a larger organisation with coordination across multiple news outlets and press conferences, the launch time was fixed for 9am on Feb 2nd 2015. Everything would happen then, apart from the odd journalist with premature timing problems – you know who you are.
Our initial plan was to leave the site up as normal, but set the maintenance page to be the launch announcement. That way if the launch overwhelmed things, everyone should see the announcement served direct from the load balancers and otherwise the site should function as normal. Plan B was to disable the forums, giving more resources to the main blog so people could comment there.
The Launch

It is a complete coincidence that our director Pete took off to go to this isolated beach in the tropics five minutes after the Raspberry Pi 2 launch.
At 9:00 the announcement went live. Within a few minutes traffic volumes on the site had increased by more than a factor of five and the forum users were starting to make comments and chatter to each other. The server load increased from its usual level of 2 to over 400 – we now had a massive queue of users waiting for page requests because all of the server CPU time was being taken generating those slow forum pages which starved the main blog of server time to deliver those fast cached pages. At this point our load balancers started to kick in and deliver the maintenance page to a large fraction of our site users – the fall back plan. This did annoy the forum and blog users who had posted comments and received the maintenance page back having just had their submission thrown away – sorry. During the day we did a little bit of tweaking to the server to improve throughput, removing the nf_conntrack in the firewall to free up CPU for page rendering, and changing the apache settings to queue earlier so people received either their request page or maintenance page more quickly.
Disabling the forums freed up lots of CPU time for the main page and gave us a mostly working site. Sometimes it’d deliver the maintenance page, but mostly people were receiving cached WordPress pages of the announcement and most of the comments were being accepted.
Super Cache not quite so super
Unfortunately, we were still seeing problems. The site would cope with the load happily for a good few minutes, and then suddenly have a load spike to the point where pages were not being generated fast enough. It appears that WP Super Cache wasn’t behaving exactly as intended.
When someone posts a comment, Super Cache invalidates its cache of the corresponding page, and starts to rebuild a new one, but providing you have this option ticked…

…(we did), the now out-of-date cached page should continue to be served until it is overwritten by the newer version.
After a while, we realised that the symptoms that we were seeing were entirely consistent with this not working correctly, and once you hit very high traffic levels this behaviour becomes critical. If cached versions are not served whilst the page is being rebuilt then subsequent requests will also trigger a rebuild and you spend more and more CPU time generating copies of the missing cached page which makes the rebuild take even longer so you have to build more copies each of which now takes even longer.
Now we can build a ludicrously overly simple model of this with a short bit of perl and draw a graph of how long it takes to rebuild the main page based on hit rate – and it looks like this.
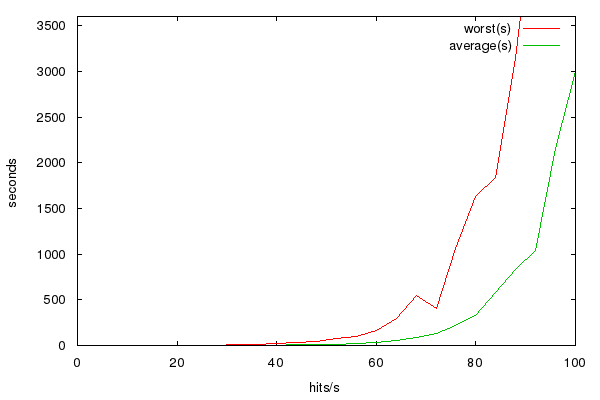
This tells us that performance reasonably suddenly falls off a cliff at around 60-70 hits/second. At 12 hits/sec (typical usage) a rebuild of the page completes in considerably under a second, at 40 hits/sec (very busy) it’s about 4s, at 60 hits/sec it’s 30s, at 80hits/sec it’s well over five minutes. At that point the load balancers kick in and just display the maintenance page, and wait for the load to die down again before starting to serve traffic as normal again.
We still don’t know exactly what the cause of this was, so either it’s something else with exactly the same symptoms, or this setting wasn’t working or was interacting badly with another plugin, but as soon as we’d figured out the issue, we implemented the sensible workaround; we put a rewrite hack in to serve the front page and announcement page completely statically, then created the page afresh once every five minutes from cron, picking up all the newest comments. As if by magic the load returned to sensible levels, although there was now a small delay on new comments appearing.
Re-enabling the forums
With stable traffic levels, we turned the forums back on. And then immediately off again. They very quickly backed up the database server with connections, causing both the forums to cease working and the main website to run slowly. A little further investigation into the InnoDB parameters and we realised we had some contention on database locks, we reconfigured and this happened.
Our company pedant points out that actually only the database server process fell over, and it needed restarted not rebooting. Cunningly, we’d managed to find a set of improved settings for InnoDB that allowed us to see all the tables in the database but not read any data out of them. A tiny bit of fiddling later and everything was happy.
The bandwidth graphs
We end up with a traffic graph that looks like this.

On the launch day it’s a bit lumpy, this is because when we’re serving the maintenance page nobody can get to the downloads page. Downloads of operating system images and NOOBS dominates the traffic graphs normally. Over the next few days the HTML volume starts dropping and the number of system downloads for newly purchased Raspberry Pis starts increasing rapidly. At this point were reminded of the work we did last year to build a fast distributed downloads setup and were rather thankful because we’re considerably beyond the traffic levels you can sanely serve from a single host.
Could do a bit better
The launch of Raspberry Pi 2 was a closely guarded secret, and although we were told in advance, we didn’t have a lot of time to prepare for the increased traffic. There’s a few things we’d like to have improved and will be talking to with Raspberry Pi over the coming months. One is to upgrade the hardware adding some more cores and RAM to the setup. Whilst we’re doing this it would be sensible to look at splitting the parts of the site into different VMs so that the forums/database/Wordpress have some separation from each other and make it easier to scale things. It would have been really nice to have put our extremely secret test setup with HipHop Virtual Machine into production, but that’s not yet well enough tested for primetime although a seven-fold performance increase on page rendering certainly would be nice.
Schoolboy error
Talking with Ben Nuttall we realised that the stripped down minimal super fast maintenance page didn’t have analytics on it. So the difference between our stats of 11 million page requests and Ben’s of 1.5 million indicate how many people during the launch saw the static maintenance page rather than a WordPress generated page with comments. In hindsight putting analytics on the maintenance page would have been a really good idea. Not every http request which received the maintenance page was necessarily a request to see the launch, nor was each definitely a different visitor. Without detailed analytics that we don’t have, we can estimate the number of people who saw the announcement to be more than 1.5 million but less than 11 million.
Flaming, Bleeding Servers
Liz occasionally has slightly odd ideas about exactly how web-servers work:

Now, much to her disappointment we don’t have any photographs of servers weeping blood or catching fire. [Liz interjects: it’s called METAPHOR, Pete.] But when we retire servers we like to give them a bit of a special send-off.




