It’s now nearly five years since we started offering IPv6-only hosting, and what started out as a source of interesting projects for enthusiastic early-adopters has become our default for most hosting requirements.
A few things have changed over the years that have made this possible:
- The death of Windows XP, the last significant OS with a browser that didn’t support SNI (Server Name Indication). SNI makes it possible for us to proxy encrypted connections to IPv6-only hosts.
- The widespread adoption of secure services. This means that protocols that don’t have their own proxying features (such as POP3 or IMAP) can be proxied in their encrypted form thanks to SNI.
- Improvements to our hosting services, such as our SSH port forwarder.
This post gives a quick run-down of how we make IPv6-only hosting a reality.
Getting bytes in
There’s no getting away from the fact that an IPv6-only hosting server still needs to be able to talk to IPv4-only clients, but there’s now a good solution for doing so for pretty much all common scenarios.
Web traffic
This is the most common requirement, and also probably the easiest, as it can be handled by our v4 to v6 proxy. The proxy is a set of servers with both IPv4 and IPv6 addresses that accept traffic for various protocols and forward it to an IPv6-only server.
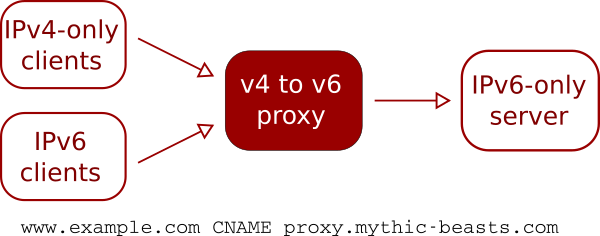
The DNS for the hosted site points at our proxy servers, by means of either an ANAME or CNAME record to proxy.mythic-beasts.com.
Unencrypted HTTP traffic is easy to proxy as HTTP 1.1 is designed to support multiple websites on a single IP address.
HTTPS is also easy to proxy, thanks to the now-ubiquitous support for SNI (its successor, ESNI, may complicate this a bit in the future, but we’ll tackle that in a separate post).
Our proxy also supports PROXY protocol, which is a standard way of communicating the original client’s IP address on a proxied connection. Support for PROXY protocol is now a standard feature of NGINX and Apache.
IPv6 traffic can either follow the same route as IPv4 traffic through the proxy (as shown above) or can be routed directly to the hosting server by setting the AAAA records for the site to point at the server rather than the proxy:
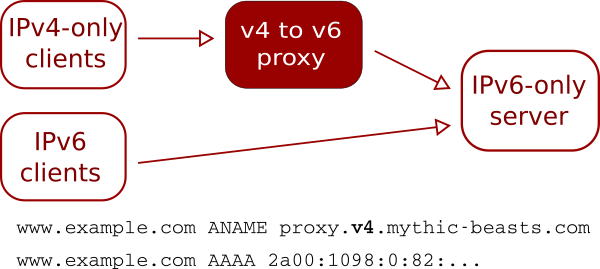
This provides a slightly more direct route for IPv6 traffic, but can make the configuration on the server a little more complicated, particularly if you’re using PROXY protocol.
IMAP and POP3
These can both be proxied in their secure forms (IMAPS and POP3S) thanks to SNI, and thankfully these secure variants are now the default choice for all popular email clients.
SSH
Our customers typically want to administer their servers via SSH, and can’t guarantee that they’ll always be connecting from a v6-enabled network. The SSH protocol isn’t built on TLS/SSL so doesn’t have SNI support, and doesn’t have any equivalent features of its own.
We work around this by providing a port-forward to all virtual servers and Raspberry Pi servers from a host with a v4 IP address, so customers can make a connection to a different host on a non-standard port, and the connection will be forwarded to the IPv6 server on port 22. Details of the host and port can be found in our customer control panel.
SMTP
SMTP is a bit awkward. It’s used in two common scenarios:
- “Submission”, where an end-user client sends outgoing mail using authenticated SMTP
- Server-to-server delivery of email.
It has multiple ports in common use:
- 25 – the standard port for server-to-server email
- 465 – a port for SMTP over SSL
- 587 – the standard SMTP submission port
Port 25 doesn’t use SSL/TLS at connection time, but can be upgraded to a secure connection via the STARTTLS command, which means it can’t be proxied using SNI.
Port 465 has a confused history, having been allocated by IANA for secure SMTP, then revoked in favour of STARTTLS and allocated to a different service, and then reinstated for secure SMTP submission by RFC 8314. Port 465 is supported by our proxy, and is a good choice for SMTP submission.
Port 587 was historically plain SMTP (RFC 2476) with STARTTLS, but is being migrated to SSL by default (RFC 8314) which is proxyable thanks to SNI. Our proxy assumes that port 587 traffic is encrypted (because it can’t do anything useful if it’s not) and as such can also be used for SMTP submission, provided you use SSL/TLS rather than STARTTLS.
For server-to-server delivery, it’s possible to use our dual-stack MX servers to handle incoming mail. This can be done by having the highest priority MX record point to the v6-only server, and then have a lower priority record
pointing to our MX servers. v4-only servers will deliver to our MX servers, and we’ll then pass it on to your v6-only server.
This isn’t a perfect solution, as it means you can’t do connection-time filtering of incoming mail.
Our MX servers need to be configured to accept mail for your domain. At present, this needs to be done by emailing support.
Getting bytes out
Your server may need to make outgoing connections to v4-only servers. Fortunately this is straightforward using our NAT64 resolvers. These are DNS resolvers that when asked for an address for a host that does not have any AAAA records will provide an IPv6 address that is mapped to the host’s v4 address. The v6 address is actually an address on one of our NAT servers that will then forward the traffic to the v4 address.
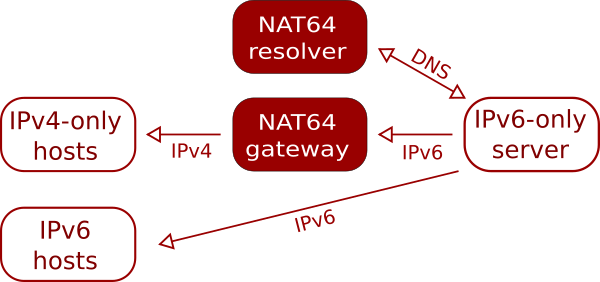
There’s a 1:1 mapping between v4 addresses and v6 addresses on the NAT server – with IPv6 we can easily allocate the equivalent of the full 32-bit IPv4 address space to a single server!
NAT64 works very well in almost all cases. We have come across a few bits of software which explicitly request an A record when doing a DNS lookup, which obviously doesn’t work.
As with any NAT configuration, you’re sharing a v4 address with other users, which can cause issues for sites that perform IP-based filtering or rate limiting.
Make the switch
Like most providers, we now charge for IPv4 addresses, but unlike most other providers it’s a tax you probably don’t need pay. We offer IPv6-only versions of all of our virtual and dedicated servers, and our Raspberry Pi servers area all IPv6-only.
Learn more
If you’d like to hear more, here are some videos of a presentation that Pete gave at the UK Network Operators Forum (UKNOF).





{kind=link}